


« Le marché boursier est conçu pour transférer de l’argent de l’actif au patient. » ― Warren Buffett
Source : gfycat.com/
Quand on évoque la Bourse, la plupart des discussions tournent autour de l’achat ou de la vente. Pourtant, peu s’attardent sur le regard du nouvel arrivant : attentes, doutes, hésitations, tout ce qui façonne les premiers pas. À force de considérer les marchés comme un terrain miné, beaucoup préfèrent rester à l’écart. Pourtant, comprendre la dynamique d’un indice, ses fluctuations, ses mouvements saisonniers, permet à chacun, du novice au plus chevronné, de prendre des décisions plus éclairées.
Pour dépasser ce plafond de verre, il existe une clé : l’analyse des séries temporelles. Cette méthode, loin d’être réservée aux experts, offre un cadre pour déceler des tendances, anticiper des évolutions et poser des choix rationnels. L’organigramme devient alors un allié, un fil conducteur pour l’investisseur.
Décortiquons ce sujet et découvrons comment l’apprentissage automatique s’invite dans la prévision des cours de Bourse.
Bourse
Une action, appelée aussi « capitaux propres », représente une part de propriété dans une société et ouvre droit à une fraction de ses actifs et de ses bénéfices, définition factuelle à l’appui. La Bourse, c’est l’espace où s’échangent ces titres, dans un système fluide d’achats et de ventes. Chaque place possède sa propre référence : New York Stock Exchange, Nasdaq, Sensex… L’indice boursier, de son côté, synthétise la valeur moyenne de plusieurs actions, reflétant la santé du marché et les tendances structurantes. Cette mécanique pèse plus qu’il n’y paraît : la Bourse façonne l’économie, touche le quotidien de millions, et savoir lire ses mouvements permet de réduire les baisses subies tout en aspirant à de meilleurs rendements.
Le fonctionnement du marché boursier
Sous sa surface, le marché boursier fonctionne comme un vaste système d’enchères : acheteurs et vendeurs négocient prix et quantités. Les sociétés arrivent via l’IPO, lèvent des fonds pour se développer, puis laissent le soin aux investisseurs de s’échanger leurs titres. Le cours de chaque action se fixe au croisement de l’offre et de la demande, dans une dynamique perpétuelle.
Au cœur du processus, l’investisseur passe ses ordres par l’intermédiaire d’un courtier. Pour acquérir, il précise la quantité désirée et le prix à ne pas dépasser. Pour céder, même logique : l’intermédiaire réalise la transaction comme convenu. Ce système repose sur la capacité à réagir vite… mais aussi sur la psychologie des foules.
Prévoir le moindre mouvement demeure un défi. Entre rationalité et instincts grégaires, données économiques et réactions humaines, la prévision boursière reste incertaine, et le brouillard omniprésent.
Machine learning en Bourse
Le marché financier refuse la linéarité. Un référendum majeur, l’annonce d’une crise, une transition politique : tout vient bousculer l’équilibre. Par nature, les données de la finance sont capricieuses et souvent indéchiffrables à l’œil nu. Les méthodes classiques peinent à isoler des motifs robustes. Le machine learning, et le deep learning plus précisément, injecte ici une nouvelle capacité : repérer les structures cachées et augmenter la finesse des prévisions.
L’apprentissage automatique se met à l’œuvre sur des volumes massifs d’historiques, attrape des motifs là où la logique humaine cale, et propose des pistes d’action concrètes pour l’investisseur. Le deep learning, capable de naviguer dans la complexité des signaux, identifie des corrélations inédites et affine la justesse des anticipations.

Source : https://gifer.com/en/7JbT
Les cours boursiers n’obéissent pas au pur hasard : ils évoluent sous forme de séries temporelles, ces successions de points de données collectés à intervalles réguliers. Pour décoder ce mécanisme, il existe des modèles sur-mesure. La star : ARIMA. Ce modèle travaille à rendre exploitables les séries les moins régulières, permettant des analyses objectives et des projections structurées.
ARIMA (Autoregressive Integrated Moving Average) gère des séries temporelles linéaires, rend les données moins volatiles et améliore les prévisions à court terme. C’est l’une des méthodes de référence plébiscitées dans les domaines financier et économique.
Mise en œuvre des prévisions de cours des actions
Cas pratique : Altaba Inc, Les données boursières de ce cas couvrent le 12 avril 1996 au 10 novembre 2017. L’idée : créer un modèle ARIMA et affiner ses réglages pour estimer le prix de clôture sur la période test.
Pour se lancer, il s’agit d’abord de charger les bonnes bibliothèques : Python, pandas, matplotlib, statsmodels. Deuxième étape, importer le jeu de données :
dateparse = lambda dates: pd.to_datetime(dates, format=’%y-%m-%d’)
data = pd.read_csv(‘/Users/Nageshsinghchauhan/downloads/ml/time_series/stock-market/aaba.us.txt’, sep=’,’, index_col=’date’, parse_dates=True, date_parser=dateparse).fillna(0)
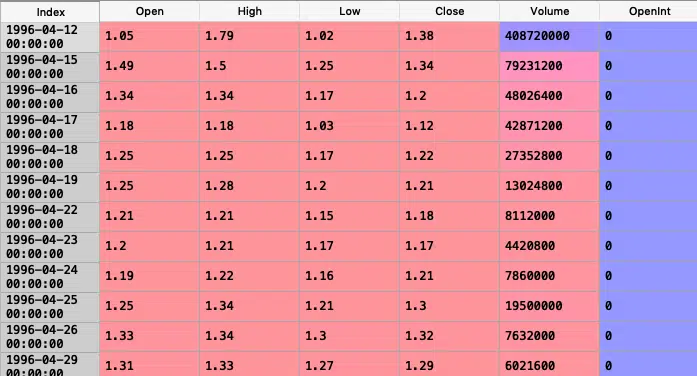
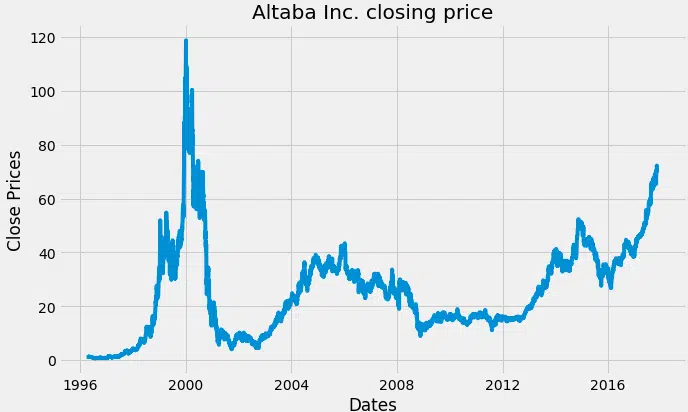
Le prix de clôture se suit à partir d’un simple graphique :
# Plot du prix de clôture
plt.figure(figsize=(10,6))
plt.grid(True)
plt.xlabel(‘Dates’)
plt.ylabel(‘Prix de clôture’)
plt.plot(data)
plt.title(‘Prix de clôture Altaba Inc.’)
plt.show()
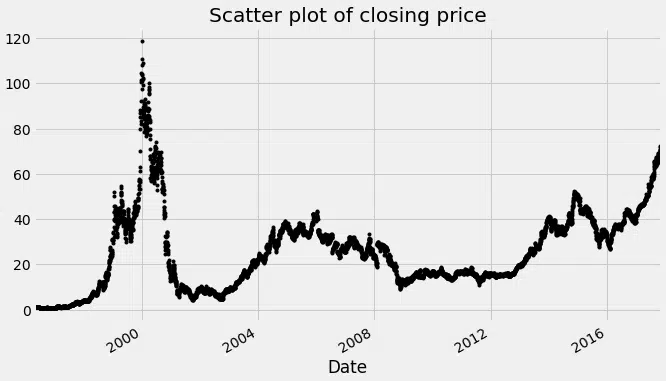
Pour compléter le diagnostic, visualiser la dispersion des points s’avère instructif :
df_close = data
df_close.plot(style=’k.’)
plt.title(‘Diagramme de dispersion du prix de clôture’)
plt.show()
Poursuivons l’examen avec l’analyse de la distribution probabiliste pour mieux cerner les variations :
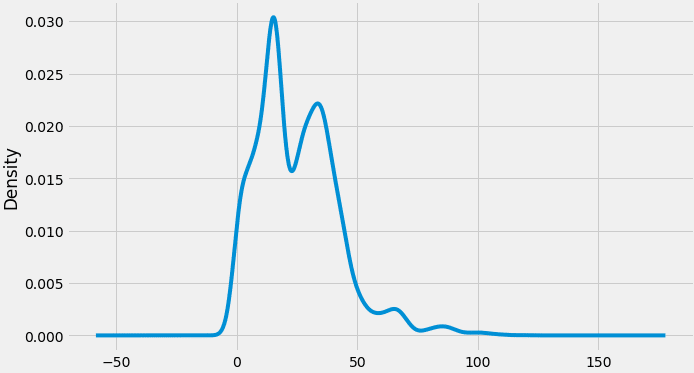
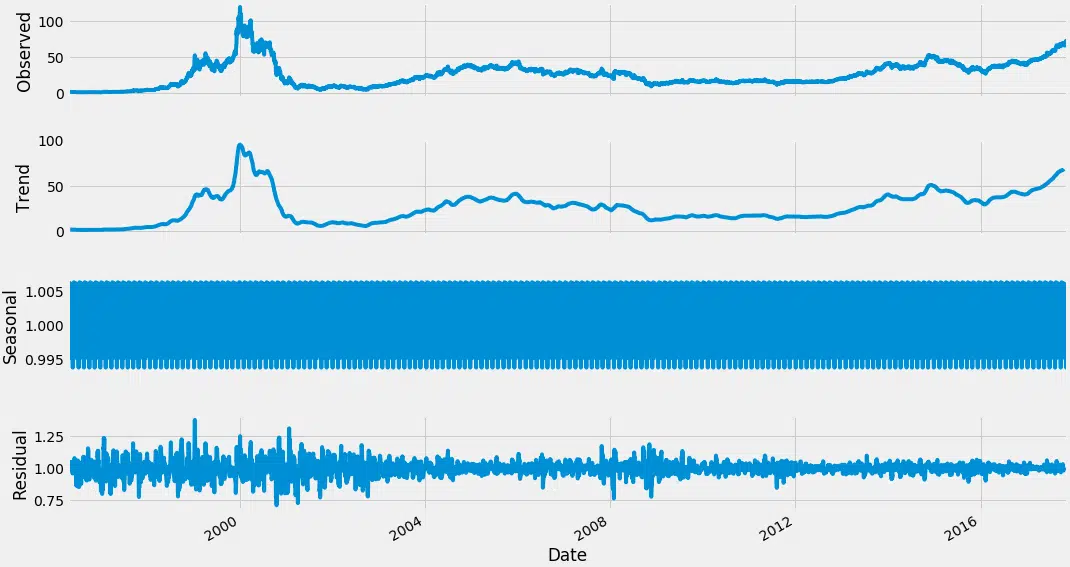
Une série temporelle s’articule toujours autour de quelques composantes détectables. Pour mieux les appréhender :
- Niveau : la valeur moyenne observée sur la durée
- Tendance : la direction générale du mouvement, à la hausse ou la baisse
- Saisonnalité : répétition de cycles courts
- Bruit : reste imprévisible et fluctuant
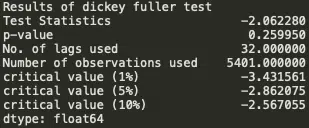
Pour pousser l’analyse, une vérification de la stabilité de la série s’impose : il faut que les données soient stationnaires pour que le modèle soit fiable.
Test ADF (Dickey-Fuller augmenté)
Le test ADF repère la présence d’une racine unitaire dans la série : en clair, il sert à trancher entre instabilité et stabilité. Les hypothèses : si l’on ne peut pas rejeter la racine unitaire, la série ne l’est pas ; dans le cas contraire, elle reste stable, c’est le graal recherché pour la suite.
Le critère : moyens et écarts-types constants doivent apparaître sur l’historique.
Pour vérifier dans la pratique :
# Test de stationnarité
def test_stationarity(timeseries):
rolmean = timeseries.rolling(12).mean()
rolstd = timeseries.rolling(12).std()
plt.plot(timeseries, color=’blue’, label=’Original’)
plt.plot(rolmean, color=’red’, label=’Moyenne mobile’)
plt.plot(rolstd, color=’black’, label=’Ecart-type mobile’)
plt.legend(loc=’best’)
plt.title(‘Moyenne mobile et écart-type’)
plt.show()
adft = adfuller(timeseries, autolag=’aic’)
output = pd.Series(adft)
print(output)
test_stationarity(df_close)
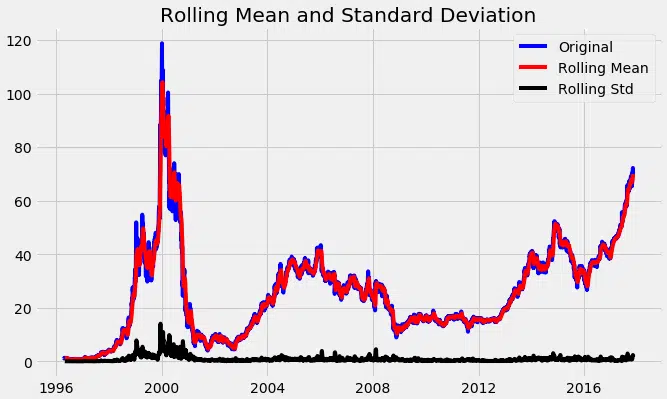
Le graphique qui en résulte montre une moyenne et une volatilité qui bougent : la série échappe à la stationnarité.
Une valeur de p nettement supérieure à 0,05, et des statistiques de test au-delà des seuils : la transformation devient incontournable.
La solution : séparer tendance et saisonnalité pour y voir plus clair :
result = seasonal_decompose(df_close, model=’multiplicative’, freq=30)
fig = plt.figure()
fig = result.plot()
fig.set_size_inches(16, 9)
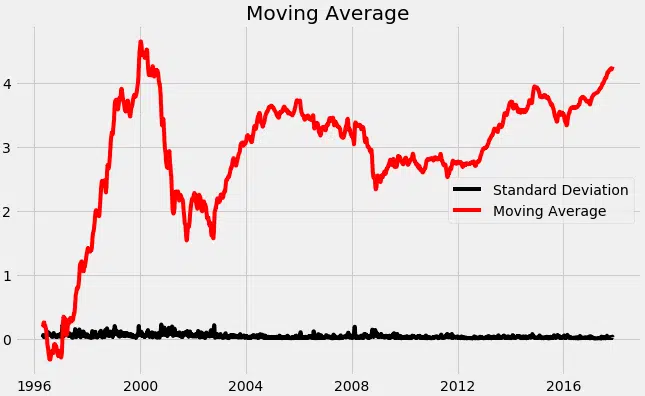
Appliquer ensuite le logarithme aide à réduire l’influence de la tendance, avant de calculer la moyenne mobile :
from pylab import rcParams
rcParams[‘figure.figsize’] = 10, 6
df_log = np.log(df_close)
moving_avg = df_log.rolling(12).mean()
std_dev = df_log.rolling(12).std()
plt.plot(std_dev, color=’black’, label=’Ecart-type’)
plt.plot(moving_avg, color=’red’, label=’Moyenne mobile’)
plt.legend()
plt.title(‘Moyenne mobile’)
plt.show()
À partir d’ici, on sépare la série en deux segments : l’un servira à l’entraînement du modèle, l’autre à l’évaluation :
# Division des données
train_data, test_data = df_log, df_log
plt.figure(figsize=(10,6))
plt.grid(True)
plt.xlabel(‘Dates’)
plt.ylabel(‘Prix de clôture’)
plt.plot(df_log, ‘green’, label=’Données d\’entraînement’)
plt.plot(test_data, ‘blue’, label=’Données de test’)
plt.legend()
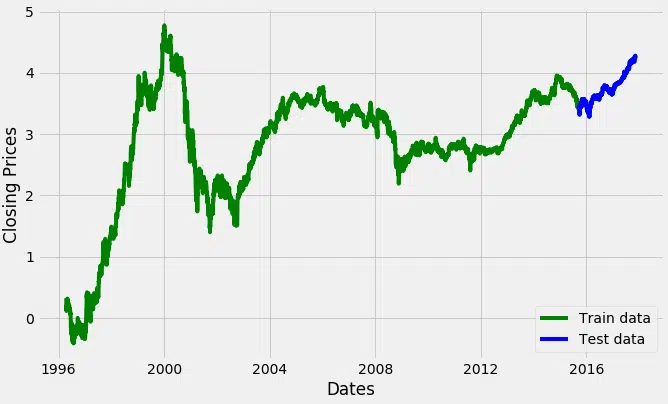
Pour trouver les paramètres du modèle ARIMA (p, d, q), Auto ARIMA automatise le passage en revue de différentes combinaisons : c’est ce qui permet d’aller vite sans inspection visuelle des graphiques ACF et PACF.
Auto ARIMA : cette fonction passe en revue les scénarios p et q, ajuste la différenciation, se penche sur la saisonnalité s’il le faut, puis retient le jeu de paramètres le plus performant.
Exemple d’appel :
model_autoarima = auto_arima(train_data, start_p=0, start_q=0, test=’adf’, max_p=3, max_q=3, m=1, D=None, seasonal=False, trace=True, error_action=’ignore’, suppress_warnings=True, stepwise=True)
print(model_autoarima.summary())
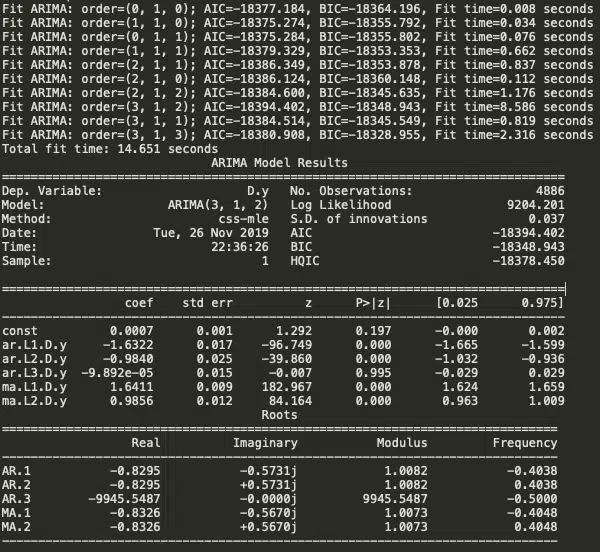
Dans ce cas, Auto ARIMA retient : p=3, d=1, q=2.
Avant de lancer la machine, il faut examiner les diagnostics des résidus :
model_autoarima.plot_diagnostics(figsize=(15,8))
plt.show()
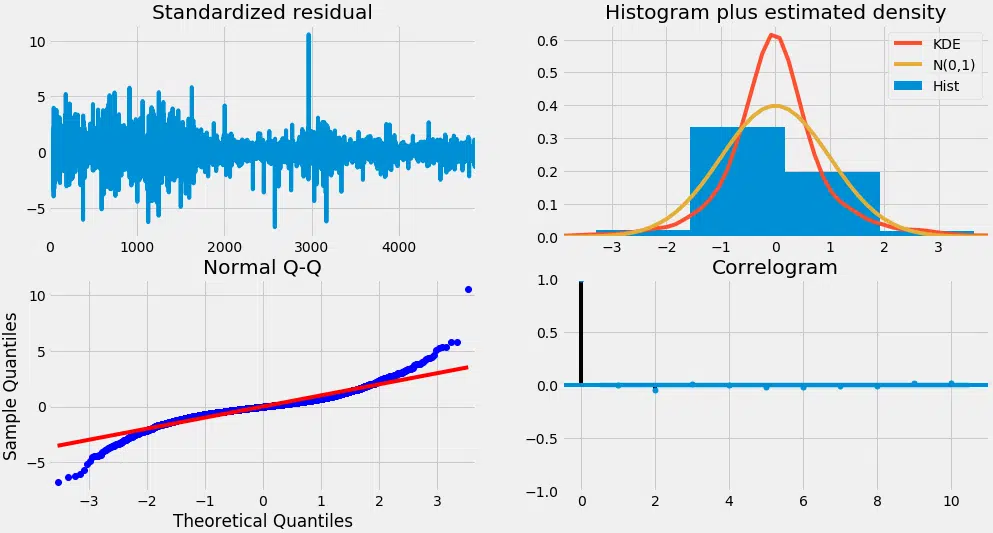
Que nous disent ces graphiques ? En haut à gauche : les erreurs résiduelles oscillent autour de zéro, sans dérive visible. En haut à droite : la densité montre une forme proche de la norme. En bas à gauche : la diagonale indique une belle symétrie. En bas à droite : pas d’autocorrélation, le reste de la variance se comporte aléatoirement. Dans l’autre cas, il faudrait ajouter encore d’autres variables explicatives.
L’ajustement paraît donc solide. Place à la projection.
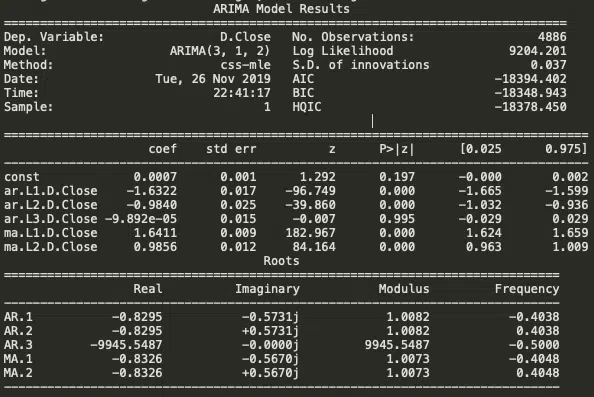
On crée le modèle final :
model = ARIMA(train_data, order=(3, 1, 2))
fitted = model.fit(disp=-1)
print(fitted.summary())
La projection s’effectue alors sur la période de test, avec un intervalle de confiance fixé à 95 % :
fc, se, conf = fitted.forecast(544, alpha=0.05)
fc_series = pd.Series(fc, index=test_data.index)
lower_series = pd.Series(conf[:, 0], index=test_data.index)
upper_series = pd.Series(conf[:, 1], index=test_data.index)
plt.figure(figsize=(12,5), dpi=100)
plt.plot(train_data, label=’Entraînement’)
plt.plot(test_data, color=’blue’, label=’Prix réel’)
plt.plot(fc_series, color=’orange’, label=’Prix prédit’)
plt.fill_between(lower_series.index, lower_series, upper_series, color=’k’, alpha=.10)
plt.title(‘Prévision du cours de l’action Altaba Inc.’)
plt.xlabel(‘Date’)
plt.ylabel(‘Prix réel’)
plt.legend(loc=’upper left’, fontsize=8)
plt.show()
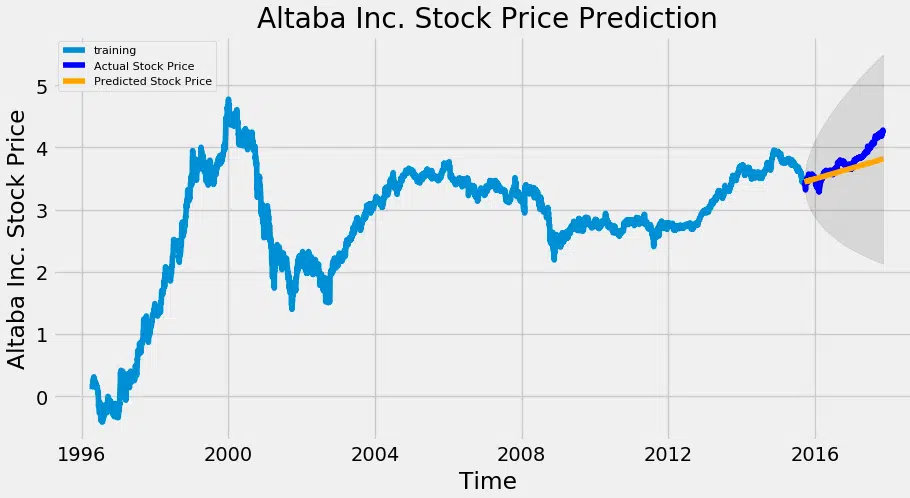
Le modèle répond présent. Plusieurs indicateurs de performance laissent entrevoir sa pertinence :
mse = mean_squared_error(test_data, fc)
print(‘MSE: ‘, mse)
mae = mean_absolute_error(test_data, fc)
print(‘MAE: ‘, mae)
rmse = math.sqrt(mean_squared_error(test_data, fc))
print(‘RMSE: ‘, rmse)
mape = np.mean(np.abs(fc – test_data) / np.abs(test_data))
print(‘MAPE: ‘, mape)
Bilan obtenu :
ESM : 0,03330921053066402
MAE : 0.13801238336759786
MSE : 0.18250811086267923
MAPE : 0.035328833278944705
Un MAPE de 3,5 % révèle que le modèle atteint une justesse de 96,5 % sur l’échantillon de test. Belle performance pour ARIMA.

Crédit : https://www.pantechsolutions.net/blog/artificial-intelligence-ai-projects/
L’essentiel se résume ainsi : la construction d’un modèle ARIMA pour anticiper les cours boursiers devient accessible, même à ceux qui partent de zéro en prévision sérieuse.
Pour aller plus loin
Les historiques, ici sourcés sur deux décennies, s’étalent de 1996 à 2017. La démarche suit les principes de Box-Jenkins (ARIMA) pour l’analyse et les estimations sur l’échantillon choisi.
Ce type d’exercice ouvre sur un horizon ample. Entre les algorithmes qui progressent, l’intuition humaine, ou la bonne vieille surprise tirée d’un détail caché, la prévision boursière n’a pas fini de dérouter. Demain, une nouvelle série donnera peut-être sa formule gagnante…

Source : diyuehb.com
Bio : Nagesh Singh Chauhan, passionné de Data Science, fasciné par le Big Data, Python et le machine learning.
Reposté avec autorisation.
À explorer également :
- Analyse du panier de marché : un tutoriel
- Introduction conviviale à la prise en charge des machines vectorielles
- Construisez votre premier Chatbot en utilisant Python et NLTK



